Kdysi dávno jsem
začal vytvářet
debianí balíčky
GNU/FDL Anglicko-Českého slovníku
pro
StarDict
. Od té doby se čas od času někdo ozve, že by se mu to hodilo i pro jinou distribuci. Kvůli obskurnosti která je zatím vytváří nebylo triviální to předělat tak, aby to produkovalo i něco jiného než balíčky pro Debian.
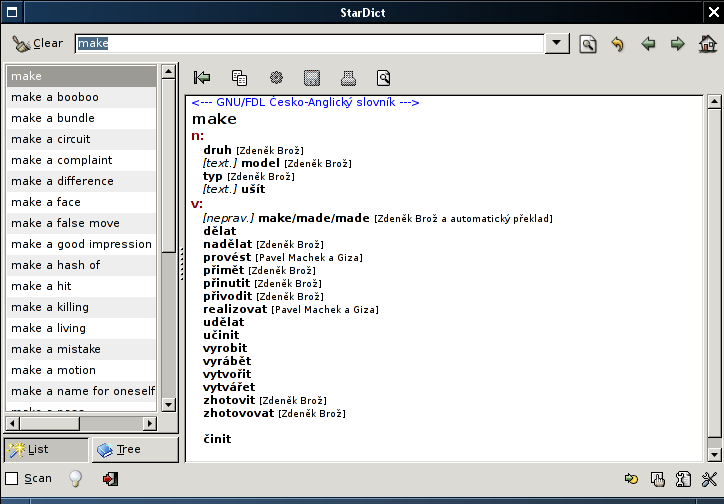
Dnes jsem se konečně rozhodl to přepsat :-). Mimo jiné se mi taky nelíbilo jak se data ve StarDictu zobrazují, takže v rámci přepisování došlo i ke změně formátu dat. A v tom jak data zobrazi je právě problém, prostě nevím jak na to, aby to vypadalo rozumně a bylo přehledné. Prozatím jsem vymyslel následující výstup, ale moc se mi to nelíbí:
ahoj
ahoy
[Zdeněk Brož]
bye
[Pavel Cvrček]
([hovor.])
bye-bye (pozdrav na rozloučenou)
[mamm]
(typ slova)
překlad (poznámka)
[autor]
Všechny položky (samozřejmě až na překlad) jsou nepovinné, takže když je na stránce více různých, je to dost rozházené. V papírových slovnících jsem moc užitečné inspirace nenašel, prostě je to jiné médium a na obrazovce je více místa. Lingea Lexicon má pěkně strukturovaná data, která asi z free slovníku nikdy nedostanu, takže tam se taky nedá inspirovat. Takže poslední možnost je, že někoho tady napadne geniální řešení jak data uspořádat, tak se předveďte :-). Jediné omezení je, že formátování lze provést jen novými řádky a tím co umí
Pango markup
.
Převodní skript prozatím žije jen v mém Arch repository, prohlédnout si ho můžete
v ArchZoomu
.
{kind=link}